As I frequently do, I’ve been taking a deep dive over the last few weeks into a very cool intersection between the WordPress and AWS ecosystems all in pursuit of the most scalable and turn key database structure for WordPress multisite.

In this post, I’ll share some of the results of my research and walkthrough how to setup an advanced database architecture using AWS Relational Database Service and Ludicrous DB, an advanced database class built for performance.
However, I want to stress that the choice of cloud providers (AWS) and database plugin (LudicrousDB) are somewhat arbitrary. While I have specific reasons for focusing on these two pieces of technology, this same architectural pattern could be achieved with any other combination of cloud provider (Azure, GCP, Digital Ocean) and database plugin (HyperDB, MultiDB).
Let’s get started by talking about each concept, remote servers, sharding, and replication, in a bit more detail.
Remote Servers
Of all the concepts we’ll talk about in this post, the idea of adding a remote server should be the most straightforward, both in terms of conceptual underpinnings and ease of implementation. In most single instance installs of WordPress, meaning when all of your site infrastructure (MySQL, PHP, Apache/NGINX) is running on the same server, we create a MySQL instance on the machine and connect to it using localhost.
There are some benefits to running things this way. First, it allows you to keep all the stuff on one machine. If you SSH into the box, from there you can get to whatever tools you need to work on the site. Second, since the web server and the database are on the same machine, there is no network latency when making a call to the database.
However, there are also a lot of reasons why this single instance install is less than ideal in certain scenarios. As your site scales, the database is likely to become the chokepoint before your PHP processes lock up. Moving your database to its own machine allows you to create a dedicated environment that is specific to SQL and can be tuned and allocated specifically for that purpose. Additionally, as we start to explore fault tolerance between the parts of our system, keeping things on one instance means everything is tightly coupled. If one part of your server locks up for any reason, they all do because all of the processes are sharing the same physical/virtual resources.
Configuring Remote Servers with Ludicrous DB
Configuring a remote database server with Ludicrous DB is no more difficult than configuring one for a single install, and there is nothing to say that you can’t use a remote database just using the basic database config in wp-config.php.
The following example is pulled from my working db-config.php file which is a drop-in config file placed in the root of the WordPress installation. You can find basic configuration instructions for LudicrousDB on the README.
$wpdb->add_database( array( 'host' => 'wordpress.remote.database.3434223.aws.amazon.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'wp_remote_db', 'dataset' => 'global' ) );
When looking at this code, there is nothing really specific about this method. In truth, we could do something like this using the default database config:
// ** MySQL settings - You can get this info from your web host ** // /** The name of the database for WordPress */ define( 'DB_NAME', 'wp_remote_db' /** MySQL database username */ define( 'DB_USER', 'root' ); /** MySQL database password */ define( 'DB_PASSWORD', 'root' ); /** MySQL hostname */ define( 'DB_HOST', 'wordpress.remote.database.3434223.aws.amazon.com' );
Insecure usernames and passwords aside, all we are doing in this scenario is pointing all of our database calls at an external IP or DNS address.
For my testing, I used the Relational Database Service on AWS to get started for the sake of simplicity. The RDS tends to be a bit on the pricey side, but some of its convenience options that we’ll explore later make it worth a look if you are considering adding some remote database servers to your site.
For additional security, I also locked down my database using AWS’ built in security group firewall settings. The database server will only accept traffic from my server’s elastic IP address or from an IP range that is assigned by my ISP at home. So, using some pretty easy to configure settings, you either have to get into the server or my home network to access the contents of the remote database.
Database Sharding
Database sharding is a complex technical concept once you start poking at the details, but on the surface it sounds pretty simple: take a large dataset, break it up in ways that make sense for the schema, and spread the load around using various architectural techniques.

In some setups, this may be an unnecessary optimization and replication would better server many read-heavy use cases. I’m going to talk about database sharding using WordPress Multisite data schema since this particular use case, especially at larger scales, seems well-suited to spreading out database load.
Default Multisite Database
In a default WP Multisite setup using a single database on a single server, we could potentially have hundreds of thousands of table jammed inside of a single database on a single database server, either remote or local.
By default, each new site added to a network adds around 10 new tables specific to that site. Once we reach a network size of around 1000, we’re looking at 10K plus tables. Each table likely has its own index, so that ends up being a ton of overhead that we place on one database and one server to keep up with.
Most of what happens when a site is added to a network reflects the default WordPress database setup, but you can also look at the specifics of the Multisite database.
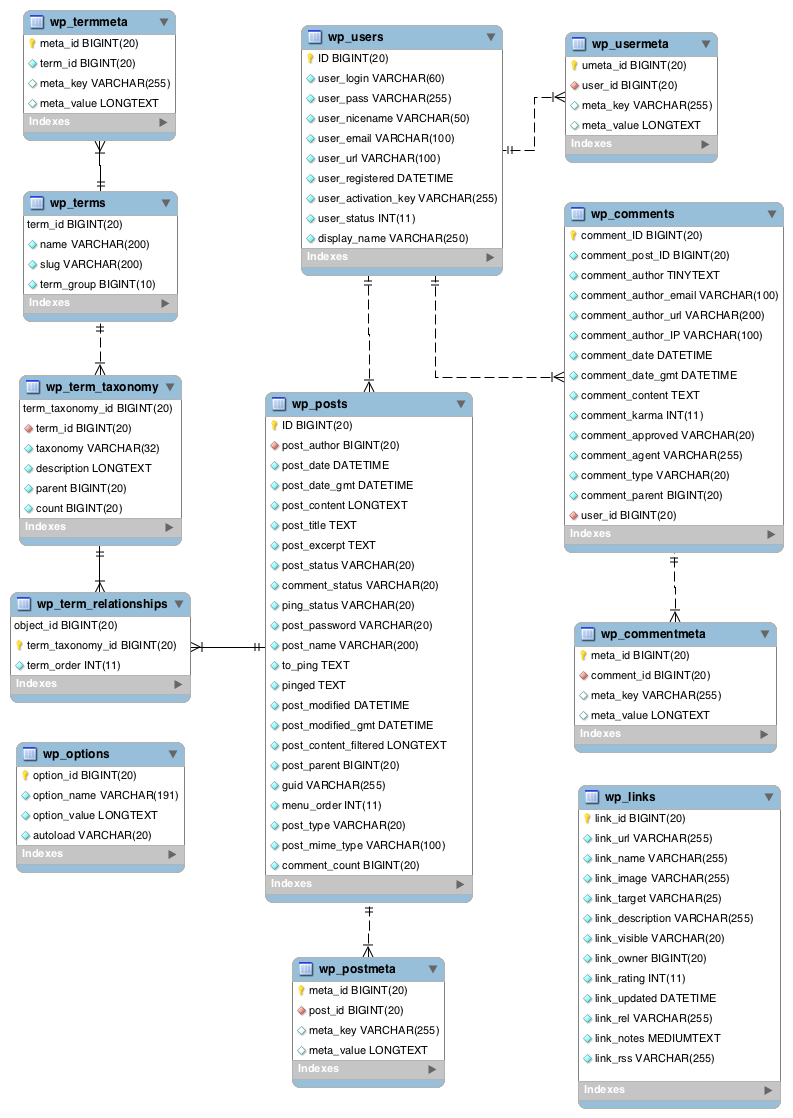
Multiple Databases, Single Server
One of the techniques that plugins like Ludicrous DB and Hyper DB allow us to start implementing is the sharding or partitioning of Multisite tables across multiple databases. To do this, we add additional databases to our config file, give them unique names as a dataset, and then write a callback function that tells the database class where to look for each table.
For example, following our Multisite data schema above, we may end up with three databases: one for global data, one for sites with an even numbered site it, and one for odd numbered sites.
Since we know that all new tables will be constructed using the following pattern, we can tap into that to help us determine how to separate our tables: wp_34_posts
The beauty here is that the number of database and their organization can be arbitrary depending on how many you want to have. The folks running Pressbooks recently wrote an article about how they moved half a million tables to 101 different databases. I’ve got my personal multisite setup using the even/odd setup, and our setup on Rampages using the md5 hash function to partition the data across 256 possible database.
Multiple Databases, Multiple Servers
After implementing the partitioning strategy above, the next logical step is to place subsets of those databases on their own machines. Given the flexible nature of the database plugins, we can also do this arbitrarily. For example, you have 101 database and the first 25 are on one database server, the next 25 on another, and so on.
Once you get to this place, the world is really your oyster.
Let’s take a look at how this works in practice though.
Implementing Database Sharding with Ludicrous DB
The first step towards implementing some sharding involves actually creating databases on whatever type of server or servers you are using. That process looks pretty similar to what it looks like to add a single dataset using Ludicrous:
$wpdb->add_database( array( 'host' => 'localhost', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_global', 'dataset' => 'global' ) ); $wpdb->add_database( array( 'host' => 'localhost', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_even', 'dataset' => 'even_sites' ) ); $wpdb->add_database( array( 'host' => 'localhost', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_odd', 'dataset' => 'odd_sites', ) );
In this example, we need to create unique names for each dataset, a term that some of these database plugins use to remove some of the confusion about whether a database means a server or a database inside of a server. For this code example, I created three datasets named “global,” “even_sites,” and “odd_sites.”
These configuration settings establish the connections necessary to communicate with these datasets. The next step involves adding a callback function to the $wpdb class that helps us compute the location of a particular table on the fly as each query is evaluated.
$wpdb->add_callback('resolve_with_dataset');
function resolve_with_dataset ($query, $wpdb) {
// Multisite blog tables are "{$base_prefix}{$blog_id}_*"
if ( preg_match("/^{$wpdb->base_prefix}\d+_/i", $wpdb->table) ) {
// break down into just wp_86_ prefix
$prefix_matches = array();
preg_match("/^{$wpdb->base_prefix}\d+_/i", $wpdb->table, $prefix_matches);
$site_table_prefix = $prefix_matches[0];
$site_id_matches = array();
// pull out any numerical matches here
preg_match("/\d+/i", $site_table_prefix, $site_id_matches);
$site_id = $site_id_matches[0];
if ( ((int)$site_id % 2) == 0) {
return 'even_sites';
} else {
return 'odd_sites';
}
} else {
return null;
}
}
There is a lot of regex going on here, but this function is actually pretty simple. In the first if statement, we are looking at the table being queried and looking for a pattern like “wp_23_” to determine whether or not this query is targeting a table used by a site on our network or the global dataset.
If null gets returned by this function, the $wpdb class assumes we are querying the global dataset. If we detect the pattern of a site on the network, we run a bit of additional regex to extract the site id from the string of the table. From there, we use the extracted site id and the modulo operator to divide the site id by 2 and evaluate the remainder.
If it’s even, our callback resolves with the even_sites dataset, otherwise it points to the odd_sites dataset. From here, we can extrapolate the basics of this callback pattern to see how we could use one hundred different datasets as a partition scheme.
It is also very easy to combine this partitioning with the idea of remote servers from the previous example. All we need to do is provide the IP or DNS address to the remote server that a particular dataset lives on, and the database plugin will be smart enough to route the query to the appropriate place:
$wpdb->add_database( array( 'host' => 'remote.wordpress.database.8787878.aws.amazon.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_even', 'dataset' => 'even_sites' ) );
These two techniques used together can be super powerful if your site usage puts a particular level of demands on your database. In the next example, we’ll look out how to make this setup even more bulletproof using replication.
Database Replication
Database replication is a complex process that connects two or more databases in a relationship often referred to as a master/slave or primary/replica. This is something that is configured at the database level, but how it typically works is that as data as written to the primary database, it asynchronously replicates those changes to the replica. Typically this replication is done with sub-millisecond latency.
The benefits of using database replication address a few different concerns when building applications for scale. First, creating replica databases allows you to spread out your database traffic across a number of different database servers that are all programmatically kept in sync with one another. Second, it allows you to reduce the surface area for the failure of your application by adding redundancy to your design. If we have a fully up-to-date read replica that we can promote to our primary instance, there is always another database waiting in the case that your primary database starts to fail.
Using some of the built in AWS tools explained below, we can also make our architecture geographically fault tolerant and deploy replicas in data centers across the country.
If you look at the steps outlined in this tutorial on creating MySQL read replicas, we can again start to appreciate the simplicity of the Relational Database Service on AWS since we can accomplish all of these steps with the click of a button using their read replica features.
Routing Read/Write Traffic with Ludicrous DB
Like most of the examples we’ve looked at using the advanced database classes, this is a pretty standard use case that is easily configured. All we need to do is add another dataset entry for our read replica, and then we add write and read properties to the database definitions.
// Primary write database $wpdb->add_database( array( 'host' => 'wordpress-remote-db-primary.h3h3k38sa.us-east-1.rds.amazonaws.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_odd', 'dataset' => 'odd_sites', 'write' => 1, 'read' => 0 ) ); // Read replica $wpdb->add_database( array( 'host' => 'wordpress-remote-db-replica.h3h3k38sa.us-east-1.rds.amazonaws.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_odd', 'dataset' => 'odd_sites', 'write' => 0, 'read' => 1 ) );
In the above example, we specific priority by setting each property with integers that get used as boolean switches. However, we can also get a bit more complex with this particular setup and take advantage of using multiple read replicas in different availability zones.
For example, if we have read replicas in both us-east-1 (Northern Virginia) and us-west-2 (Oregon) we can specify a topology for our data centers so that our application reads out of the more performant database first.
// Read replica us-east-1 in Virginia $wpdb->add_database( array( 'host' => 'wordpress-remote-db-replica.h3h3k38sa.us-east-1.rds.amazonaws.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_odd', 'dataset' => 'odd_sites', 'write' => 0, 'read' => 1 ) ); // Read replica us-west-2 in Oregon $wpdb->add_database( array( 'host' => 'wordpress-remote-db-replica.h3h3k38sa.us-west-2.rds.amazonaws.com', // If port is other than 3306, use host:port. 'user' => 'root', 'password' => 'root', 'name' => 'multisite_site_odd', 'dataset' => 'odd_sites', 'write' => 0, 'read' => 2 ) );
Since our web server is also located in us-east-1, we can take advantage of the high throughput network available in the same data center. But if for whatever reason that replica is inaccessible, we can fallback to a replica available across the country. This same configuration could be continued for as many layers as needed based on the requirements of the application.
Wrapping Up
As far as web applications go, WordPress in some ways has the lowest barrier to get started, but there are lots of performance bottlenecks that can creep up if things aren’t properly configured. For most people, the strategies outlined here may be unnecessary after implementing easier things like NGINX and static page caching, but nevertheless, more popular sites will run into some database performance issues at some point in time.
Like I said in the beginning, these strategies can be modified based on your preferred cloud provider and the level to which you feel the need to implement these patterns. As with most things, I write these posts to share some of what I learn on my long trips down rabbit holes.
If you have already implemented pieces of this, or need help/guidance in doing so, make sure to let me know in the comments below.
We wanted to know if we can hire you to help us with setting up Ludicrous DB and AWS within our multi-site? Kindly let us know if you can and what your fees would be.
Hey Ryan,
Thanks for reaching out. I’m going to follow up with the email you left with the comment.
Regards,
Jeff
Hi,
is I need to add the above code into wp-config.php or somewhere else?
In wp-config.php there is no definition for $wpdb->add_database()
Hey Rihan,
Yeah, all of that code will do in wp-config.php, but you need to install the database plugin and swap out some of the files as mentioned here in the docs. That should add the methods on the $wpdb class. Let me know if you have any other issues.
Thanks for reading,
Jeff
Hi
how can we use the above to use for example 16 DB’s in round robin? instead of odd and even?
That’s a great question. After rereading through the configuration options, I’m not sure there is a native way to achieve that since each query would need to know about the previous query to determine it via callback. If you assign 16 datasets the same preference level, they would get hit randomly, but that is not round robin. I think you’d need to extend that database class to cache information about each request somewhere such that it can be accessed each time a new request is made. It sounds like an interesting problem though, so feel free to post back if you figure something out or want some ideas for other ways to partition your datasets. Thanks for reading, Jeff
hi,
great job !
can you let me know example code (Implementing Database Sharding with Ludicrous DB) for making multisite blogs assign to the databases just like how press books works with 101 dbs (last 2 digits to database name) instead of going with odd and even , because I expect a huge growth in my multisite which even using WooCommerce which is resource intensive. so having great number of databases would help me do it, please help me in this
your guide help me a lot. Thank you so much
Very interesting article. Came across this while searching for geo-partitioning in context of woocommerce when hosted in multisite. Does this structure work when the shards are hosted in separate geographically separated DBs limited by cross-country data sovereignty requirements? Any limitations or special approaches you may have come across like latency, caching, elastic search etc.
Great, thanks for this information. Would there be any limitations for accessing the data in the additional databases using plugins, e.g. search and filter plugins?
Generally, no. As long as the plugin uses appropriate WordPress APIs to interact with the databases, these plugins route the requests in the correct way.
Is there a way to only sync a post type and its post meta? For example, post_type=products and those products most meta while using a call back like:
global $wpdb;
$wpdb->add_callback( ‘db_callback’ );
function db_callback( $query, $wpdb ) {
if ( $wpdb->base_prefix . ‘posts’ == $wpdb->table || $wpdb->base_prefix . ‘postmeta’ == $wpdb->table ) {
return ‘wpposts’;
}
}
So wonderful. I am trying out to set up my big news site that could en up million posts. Thank you very much!