In a previous post, I wrote about some of my experiences building chatbots with the Amazon Lex platform, and I guess this post will represent the culmination of that experimental work into a production ready tool. Throughout this process, I’ve learned a lot more about building applications using AWS services, but it has also helped me clarify a lot of my own philosophies on how and when we should be deploying certain types of technologies.
Enter the Virtual Assistant
I started this project with the broad goal of helping to alleviate some of the burden of answering repetitive questions off our Online@VCU staff. After looking at over a year’s worth of email and contact form submissions, we realized that most of the “soft-ball” questions fell into a few clearly defined buckets and had fairly predictable answers, most of which redirected the student to another office or website of VCU.
In my initial interface design iterations, I really played up the idea of the chatbot, almost making fun of the idea that you were talking to a robot and calling attention to the artificiality of the whole thing. While that was pretty playful, it didn’t really capture the serious “I can help you vibe” I wanted to communicate to anyone using the tool.
So, I took a page out of the corporate America playbook and renamed the chatbot to a virtual assistant and pared down the playfulness to reflect a more reserved but clean interface. 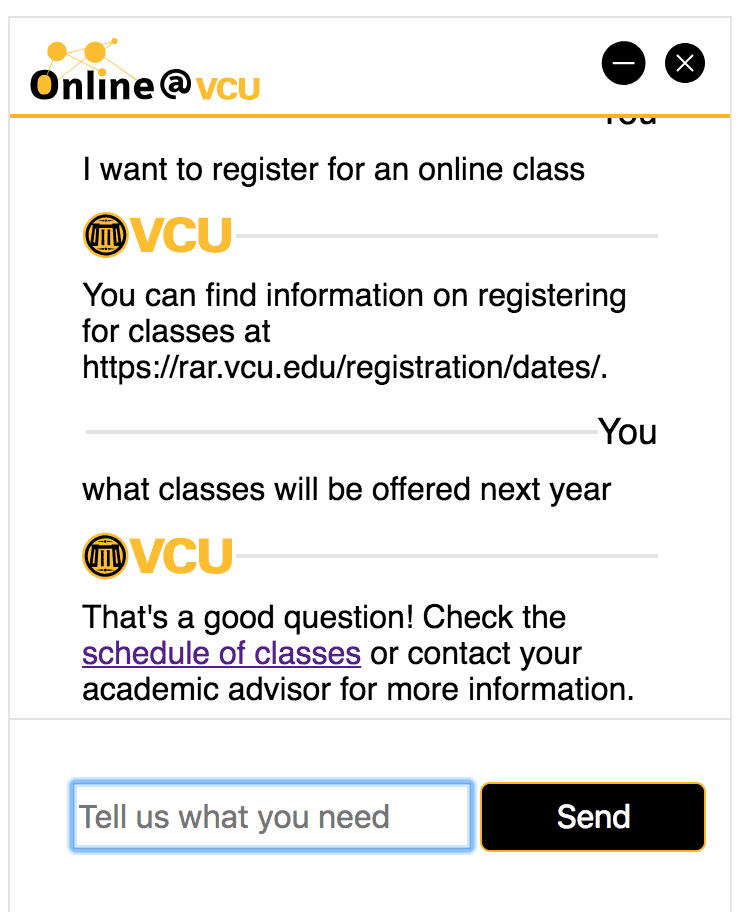
There are so many things I learned during this project, including some pretty slick CSS tricks using flexbox, so it’s tough to really draw edges on the main takeaways from this experience.
However, I think it was still pretty difficult to use the Amazon Lex platform to make a bot exposed over HTTP, so I’ll focus my thoughts on this post to some of those challenges. If you want a great CSS tutorial though that gives you some immediately actionable tips, check out this “Even More CSS Secrets” presentation.
Getting Lex and Lambda Working
In the first post, I go through most of what you might need to know about creating a language interaction model for the Lex platform, but that focused on querying an external data store to fulfill a request. In this scenario, I wanted to make the Lex model that was available over HTTP so that a JS client on any site could talk to the bot.
I won’t go into the API Gateway configuration of Lambda to be open to the web. I was able to modify some of the code in this guide to get an endpoint to pass messages to Lex.
However, this is really the brains of the operation, as the UI passes messages to a Lambda function that communicates directly with Lex and logs the interactions in a DynamoDB table:
var AWS = require('aws-sdk');
exports.handler = (event, context, callback) => {
try {
var message = event["body-json"];
// ************************
// validate and filter bad/empty messages
// ************************
if(!message.hasOwnProperty('body')){
var error = new Error("Cannot process message without a Body.");
callback(error);
}
else {
// ************************
// Message is valid so now we prepare to pass it along to the Lex API.
// ************************
AWS.config.region = 'us-east-1';
var lexruntime = new AWS.LexRuntime();
//userID is a timestamp of when the user initiated the first chat
var userID = message.userID
var timestamp = message.timestamp
var params = {
botAlias: 'botAlias',
botName: 'botName',
inputText: message.body,
userId: userID.toString(),
sessionAttributes: {
}
};
//create a second object of data to save
var dataToSave = {
TableName: 'QuestionsTable',
Item: {
"timestamp": timestamp,
"question": message.body,
"userID": userID
}
}
var docClient = new AWS.DynamoDB.DocumentClient()
docClient.put(dataToSave, function(err, data){
if (err){
console.log(err)
} else {
console.log("Added item: ", JSON.stringify(data, null, 2) )
}
})
lexruntime.postText(params, function(err, data) {
if (err) {
console.log(err, err.stack); // an error occurred
callback(err, 'Sorry, we ran into a problem at our end.');
} else {
//Save the Bot's response for further analysis
var botResponse = {
TableName: 'QuestionsTable',
Item: {
timestamp: Date.now(),
question: data.message,
userID: userID,
bot: "VCU"
}
}
docClient.put(botResponse, function(err, data){
if (err){
console.log(err)
} else {
console.log("Added item: ", JSON.stringify(data, null, 2) )
}
})
console.log(data); // got something back from Amazon Lex
callback(null, data.message);
}
});
}
} catch(e) {
console.log(e);
callback(e);
}
};
Overall, this isn’t a ton of code, partially because Amazon’s SDKs for their services are so succinct. However, the gist of what we’re doing is intercepting a POST request to an API endpoint, taking that message and logging it to a DynamoDB table before passing it off to the Lex model, then we wait for a response from Lex, at which time we log the bot’s response to DynamoDB and return the response to the user.
Making Sense of Fragmented Conversations
One of the downsides of exposing Lex through and HTTP endpoint in this manner is that you lose the ability to access all of the missed utterances that Lex didn’t understand. At the same time, given the existing analytics in the Lex service, you can’t really tell either what may have been a false positive, something that Lex thinks it understood but didn’t, which is likely more dangerous than a false negative since the response will be just wrong.
So, to combat this, I decided to extend this prototype with a DynamoDB integration to act as an anonymous log of all of the conversations. 
The structure of the DynamoDB table looks like the image above. Each entry has a unique timestamp in milliseconds of when the message was passed through Lambda, while there are repeated timestamps of when the user first opens the chat dialogue in milliseconds so that we can tie messages and responses together into on threaded conversation.
Anything that comes from our Lex bot automatically gets tagged with an additional ‘VCU’ attribute so that we can tell it is a response from our models.
Overall, this is pretty bare bones data, and all totally anonymous. Since we’re using JavaScript to power the entire Virtual Assistant, there is a lot more we could grab if we cared to do so. However, since this project is still in the nascent stages, we figured it was best to just collect enough data to determine frequency of usage and what questions people are asking to better train the models.
Where to Go From Here
I haven’t thought a ton about what the next steps are from here for this project, other than making the Lex bot smarter by adding additional intents or refining our existing models with new input. However, my initial prototypes were much more involved and allowed for some searching and filtering of external course and program feeds. That will likely be a next step, but it is good to place a checkmark next to this in some form since I’ve been tooling with this for the better part of a year.