Over the last couple of weeks, there has been some renewed interest in a project I started a few years back, our Online@VCU virtual assistant (aka chatbot), that is created using Amazon Lex, Lambda, and DynamoDB.
We launched the chatbot with maybe 10-15 intents, mostly focused on prospective and current students, but as a part of the ongoing COVID-19 flux, we’re also looking at expanding its usage to include other types of users and a broader range of intents.
To help us in this regard, I made some additional modifications to the application so that we can collect and analyze more data about what types of people are using the bot, where they are at when they use it, and when.
Designing data models in DynamoDB was a new experience for version 1 of this project, and it has taken awhile to wrap my head around the best way to model data in a single table design. My shortcomings here were immediately exposed as we tried to pull data from the DynamoDB table for analysis. In this post, I’m going to talk through some of the ways I had to change the table to accommodate different access patterns.
I’m still not entirely happy with how things are working, and it’s very possible that DynamoDB isn’t the best technology choice for our use case, or I don’t really know what I’m doing enough to make it work. Either way, this partial debrief should help me clarify my own thinking here a bit.
Single Table vs Relational
Coming from a background where most of my database work has been in some way relational, it has been difficult to adapt myself to designing data models using only a single table.
For example, in a relational model for our chatbot application, we might have two main entity types with their own tables: Conversations and Message.
A Conversation happens anytime someone kicks off a chat session, and then there is a many-to-one relationship between Messages and the parent Conversation.
If I were to model this in a relational way and normalize the data, I’d likely wind up with something like this:
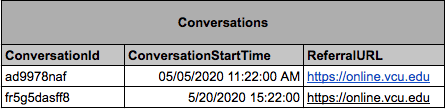
Our base entity would be a conversation that would hold all of the data about the conversation itself, which could be joined with our Messages table:

As you can see there isn’t a ton of data being stored for each conversation or message, and for most access patterns we can get the data we want by performing a simple join across these two tables.
However, joins on large data sets are expensive, and as such DynamoDB has even eliminated the ability to do joins as a feature to promote scalability.
Now, even though we can’t do joins through a direct interface with the database in DynamoDB, we can simulate a join using application code. In other words, I could write code that does something like this:
function joinDataSets() {
const allCoversations = getAllConversations()
allConversations.forEach(conversation => {
const messages = getMessagesByConversationId(conversation.ConversationId)
conversation.messages = messages
}
return allConversations
}
In reality, there is a lot more code we would need to write, but you should get the drift from this example: we get a list of conversations, then use those conversationIds to get a list of all the messages for each conversation.
Instead of relying on the database layer to automatically join our data, we could just offload that process onto our application somehow if we really wanted to keep all of our data normalized. While this isn’t the recommended practice in DynamoDB, I’ve done something similar using Firebase and MongoDB when we wanted to establish a normalized relationship between two pieces of data.
After some mucking around with options in DynamoDB, and having to abandon my initial single table design, I came up with the following data model for the ChatbotQuestions table:

One of the features of DynamoDB that helps us organize denormalized records is the ability to establish a compound primary key for each record. In this case, our compound primary key is the conversationId attribute as the partition key and the messageDateTime attribute as the sort key.
What this means in practical terms is that all of the items with the same partition key value for conversationId are stored together, and then are sorted using the messageDateTime sort key attribute. This type of organization is what makes DynamoDB so scalable because with the way we’ve constructed this table it is very quick and efficient to get all of the messages with a particular conversationId value.
Now that we have a decent table in DynamoDB, we can talk about how the decisions we’ve made regarding table design impact how we query and access this data using the AWS SDK for DynamoDB.
Querying and Scanning DynamoDB Tables
It took me awhile of working with the DynamoDB SDK to start to wrap my head around the operations that you can use to retrieve data and the various expressions we use to filter or limit a result set. In most cases, when reading data from DynamoDB, you will either use the query or the scan operation.
However, to understand the performance implications of both operations, we need to talk about read capacity units and the limitations of scan. Read capacity units are a measure of how much reserved throughput we have on the DynamoDB table we’re working with. Essentially, what this means is that you pay for a guaranteed max number of read/write operations per second on a slice of your data 4KB in size.
To put this in other words with an example, if we have 5 read units provisioned (the free tier default), we can read up to 20KB per second (5 read units * 4KB data size) before our operations begin to get throttled.
Personally, I find this aspect of AWS billing incredibly pedantic to work through, but if you understand the basic equations you can make some commonsense decisions about how to retrieve your data since different methods have different implications for read capacity.
The Difference between Query and Scan
The two main methods I’ve used to read data from DynamoDB are the queryand scan operations. Each method has a pretty specific use case and some additional constraints or limitations that should be considered from a performance standpoint.
Understanding Query in DynamoDB
First we’ll take a look at the query operation of the DynamoDB client, which uses primary key attribute to perform an efficient lookup when we have the primary key of our record already. The benefit of using a query operation as opposed to a scan is that we only consume read capacity for the records that are returned from our query, not the total size of the table.
This being said, it’s ideal for you to design you DynamoDB tables in a way that takes advantage of this feature of the query operation.
const documentClient = new AWS.DynamoDB.DocumentClient();
const params = {
"TableName": "ChatBotConversations",
"ProjectionExpression": "conversationId, messageDateTime, messageText, userType, referralURL, messageStatus",
"KeyConditionExpression": "conversationId = :conversationId",
"ExpressionAttributeValues": {
":conversationId": parseInt(queryString.conversationId)
}
}
documentClient.query(params, function(err, data){
if (err) {
console.error("Unable to query the table. Error JSON:", JSON.stringify(err, null, 2));
callback(err)
}
try {
callback(null, {
statusCode: 200,
body: JSON.stringify(data.Items),
headers: {
'Access-Control-Allow-Origin': '*'
}
})
}
catch(error) {
console.log(error)
}
})
Most of the actual parts of our query are contained in the parameters object that we pass to documentClient.query, so we can take a look at those line in more detail.
The TableName property should be self-explanatory, as that is the name of the table we are querying. The ProjectionExpression property allows us to specify which values from the table will be returned. If we don’t specify a ProjectionExpression, then by default all of the values for each record are returned.
To perform a query, we are required to provide an equality expression for our partition key in KeyConditionExpression property, meaning we have a “lookup” a particular record using its primary key.
"KeyConditionExpression": "conversationId = :conversationId",
"ExpressionAttributeValues": {
":conversationId": parseInt(queryString.conversationId)
}
As you can see in this example, we also using something called ExpressionAttributeValues in conjunction with our KeyConditionExpressionproperty. The way that I look at this coming from a SQL background is that ExpressionAttributeValuesare just the DynamoDB equivalent of parameterizing your query. Since we don’t want to pass a literal value into our expressions, we use the ExpressionAttributeValues property to pass our query parameters dynamically at run time.
In short, the query operation is helpful when we know the partition key of the items we want to retrieve. If we’re using a compound primary key with a sort key, we can do a small amount of filtering using other conditions on that value. One of the key points to remember about query vs. scan is that a query only consumes read capacity based on what the query returns.
Understanding Scan in DynamoDB
The scan operation is what you might use if you need to run a query over all of the records of your database table, and because it looks at every record in your table it has huge performance implications as your tables get larger. Whereas a query will only consume read capacity units based on the items returned, a scan operation consumes read capacity units based on the total number of items it evaluates. There is also a 1 MB limitation on how much data can be evaluated in a single scan, after which you have to essentially paginate your scans.
Let’s take a look at an example that queries all conversation in the last seven days:
const documentClient = new AWS.DynamoDB.DocumentClient();
const today = new Date.now()
const params = {
"TableName": "ChatBotConversations",
"ProjectionExpression": "conversationId, messageDateTime, messageText, userType, referralURL, messageStatus",
"FilterExpression": "conversationId BETWEEN :sevenDaysAgo AND :now",
"ExpressionAttributeValues": {
":sevenDaysAgo": today - (7 * 24 * 60 * 60 * 1000) ,
":now": today
}
}
documentClient.scan(params, function(err, data){
if (err) {
console.error("Unable to query the table. Error JSON:", JSON.stringify(err, null, 2));
callback(err)
}
try {
callback(null, {
statusCode: 200,
body: JSON.stringify(data.Items),
headers: { 'Access-Control-Allow-Origin': '*' }
})
}
catch(error) {
console.log(error)
}
})
Most of the params object should look similar to the previous example, with the exception of changing our KeyConditionExpression property to a FilterExpressionproperty. The FilterExpressionproperty allows for a more expansive set of comparison operators than the KeyConditionExpression property does, but we essentially interpolate the values in the same way using the ExpressionAttributeValues property.
Lessons Learned
Overall, it seems helpful to share some of the lessons I’ve learned while iterating on this project over the last few years.
First, it seems OK for me to admit in this context that DynamoDB may no be the best choice for my application for at least a few reasons that are now apparent to me after having worked through a lot of this.
One of the benefits of DynamoDB is its scalability, but the performance benefits we get in this area are outweighed by difficulties in some others, namely in the awkwardness of adding additional access patterns and the difficulty of performing analytics on our collections of conversations and messages.
This project has morphed from a pet project to a prototype to something we’re considering doubling down in, but expectedly our requirements and needs have changed along the way. Alex DeBrie (who literally wrote the book on DynamoDB) describes cases where developer flexibility is important as being not well-suited to DynamoDB because it is so onerous to change things once you’ve gotten moving. I can attest to this after having started with one data model and having to switch to another mid-stream.
Another point in DeBrie’s article on single table design suggests that DynamoDB isn’t well suited for analytical queries, which is also another sticking point in this project. In certain ways, while the transactions (e.g. chatbot conversations) themselves are important for us, it is the ability for us to analyze them at scale to look for patterns that is most valuable. My work to get these message out of DynamoDB and into a spreadsheet was indeed difficult, and perhaps needlessly so.
It’s not often that we hear technologists openly admit that they made a bad, or perhaps uninformed choice, about the technologies used to build an application, but this has been such an informative part of my learning process that it’s worth sharing this publicly.
If nothing else, I now understand in finer detail both WHEN and HOW to use DynamoDB to its fullest advantage. At the end of the day, it’s very likely that our application will never grow to the scale where I have to pay the blood price for these poor choices, but at least I’ll view future experiences through this lens of difficulty before I get started.
If you’re interested in reading about prior iterations of my work with Amazon Lex making conversational interfaces, check out these articles: